Method
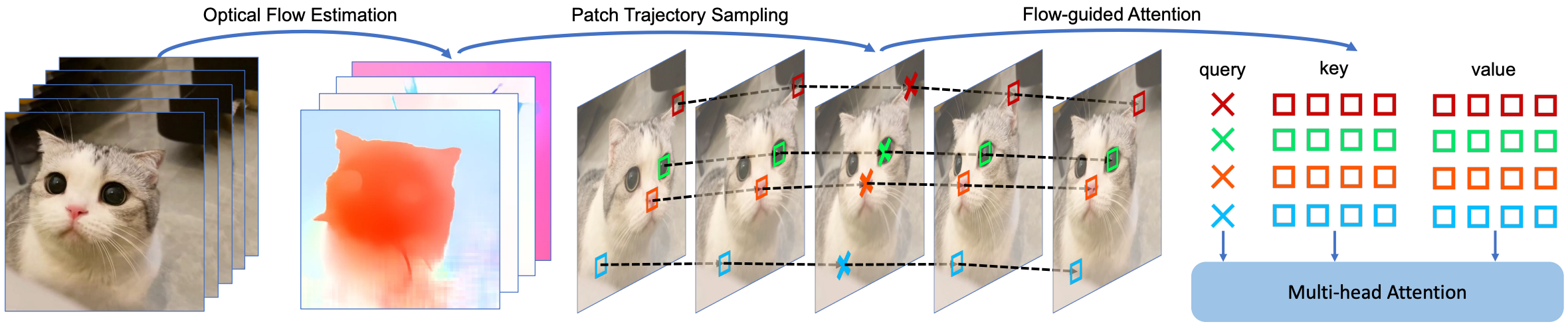
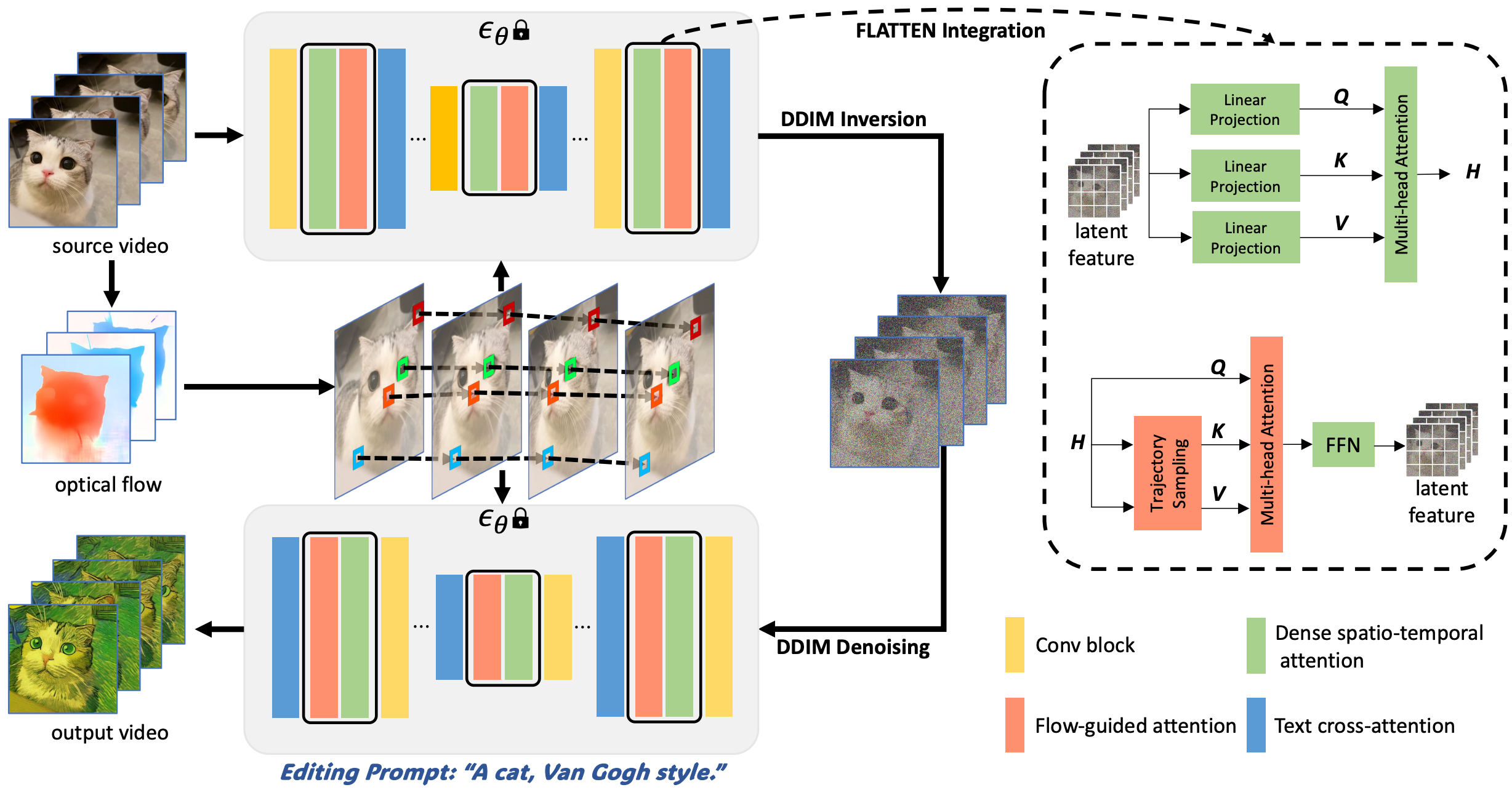
In this work, we propose a novel (optical) FLow-guided ATTENtion that seamlessly integrates with text-to-image diffusion models and implicitly leverages optical flow for text-to-video editing to address the visual consistency limitation in previous works. FLATTEN enforces the patches on the same flow path across different frames to attend to each other in the attention module, thus improving the visual consistency of the edited video. The main advantage of our method is that enables the information to communicate accurately across multiple frames guided by optical flow, which stabilises the prompt-generated visual content of the edited videos. Furthermore, our proposed method can be easily integrated into other diffusion-based text-to-video editing methods and improve the visual consistency of their edited videos. We present a T2V editing framework utilizing FLATTEN as a foundation. Our training-free approach achieves high-quality and highly consistent text-to-video editing.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}